

芯片战争新思路:用英伟达的方式,抗衡英伟达
芯片战争新思路:用英伟达的方式,抗衡英伟达

6 月 6 日,英伟达市值达到了 3.01 万亿美元,超过苹果成为全球市值第二高的公司,仅次于微软。
而去年此时,英伟达的市值刚刚突破万亿美元,成为美国第七个,也是史上第九个跻身万亿市值俱乐部的科技公司。
当年的曹阿瞒,如今已成为了曹丞相。
" 规模达 3 万亿美元的 IT 行业,即将打造的商品能够直接服务于 100 万亿美元的其他行业。这个商品不再仅仅是信息存储或数据处理工具,而是一个能为各个行业生成智能的工厂。" 英伟达创始人兼 CEO 黄仁勋 6 月 2 日在 Computex 2024(2024 台北国际电脑展)上发表主题演讲时志得意满。
在生成式 AI 时代,英伟达的成功无需赘述。尽管台下站满了挑战者,包括老对手英特尔、AMD,大厂华为、谷歌、微软,以及国内独角兽摩尔线程、寒武纪、壁仞科技等,不时还有英伟达的 " 裂缝 "" 破绽 " 等分析文章,挑战者不可谓不强,分析也不是没有道理,但英伟达的市值说明了一切。
但是,这并不意味着其它芯片厂商就没有机会,关键是要找到合适的方法。
面对号称拥有的八十万大军的曹操,江东群儒议论纷纷,甚至有人喊出:" 曹操虽挟天子以令诸侯,犹是相国曹参之后。刘豫州虽云中山靖王苗裔,却无可稽考,眼见只是织席贩屦之夫耳,何足与曹操抗衡哉!"
面对强势的英伟达,国内妄自菲薄之声也不少,就像当年的江东群儒一样。
但也有人在思考 " 破曹之策 "。曹操此前赢得官渡之战,来自乌巢的一场火。而赤壁之战前,诸葛亮和周瑜写在手心的默契也是 " 火 "。
用英伟达蚕食英特尔市场的方式,来与英伟达抗衡,就是芯片厂商欲燃起的 " 火 "。
1. 改变 CPU 依赖
上世纪 80 到 90 年代,是英特尔及其 x86 架构主导的年代。
x86 架构始于 1978 年,当时英特尔公司推出了 16 位微处理器 8086。由于以 "86" 作为结尾,因此其架构被称为 x86。
到了 1997 年,全球超过 90% 的个人电脑和数据中心都搭载了英特尔的 CPU(中央处理器),计算机内部大部分的互联协议、接口标准、芯片组和主板标准、内存标准、网络标准等,都是由英特尔定义的。
那个年代,还有不少公司也在开发 CPU 这种执行输入计算机的命令的通用芯片。不过,上世纪 90 年代初,SunSoft 公司有三位工程师(两位工程师、一位合作工程师)被委派构建一种可以与 CPU 一起插入 SunSoft 工作站并可以在屏幕上渲染图形的芯片。
这款芯片被认为是英伟达 GPU(图形处理器)的前身,而这三个人是克里斯 · 马拉科夫斯基(Chris Malachowsky)、柯蒂斯 · 普里姆(Curtis Priem)和黄仁勋。
1993 年,他们三个人共同创立了英伟达,他们并没有选择研发 CPU 直接与英特尔竞争,而是选择入局基于图形和视频游戏的计算卡市场。
尽管英伟达首款产品 NV1 卖得并不好,但是 1997 年其推出的 128 位 3D 处理器 RIVA 128 在四个月内出货量突破 100 万台;1999 年推出的 GeForce 256 更是成为了当时的爆款产品,图形计算卡也因此有了一个新的名字—— GPU。
GeForce256 的革命性突破在于 T&L 引擎(Transforming&Lighting,坐标转化和光照计算)的加入,这使得显卡能够进行大量浮点运算,并将原本依赖 CPU 的 3D 计算剥离到显卡上,从而释放了大量 CPU 资源。这让游戏运行更流畅的同时,也大幅提高了画面的精细度。
因此,GeForce256 直接改变了业内的竞争格局,之前用 " 高端 CPU" 才能完成的工作,变成了用 " 常规 CPU+GeForce256" 就能完成,而且流畅度更好。
这意味着,一部分用户对 CPU 的依赖,逐渐转到了对 GPU 的依赖。
CPU 和 GPU 是计算机中两种不同类型的处理器,CPU 设计用于执行广泛的计算任务,特别是顺序处理和复杂逻辑,拥有较少但功能强大的核心;而 GPU 则专为处理大量并行计算任务而设计,如图形渲染和视频处理,拥有大量但功能相对简单的核心,使得 GPU 在处理多线程和数据密集型任务时更为高效。

CPU 和 GPU 的对比,图片来源:英伟达
英伟达最初设计 GPU 是为了给《光环》和《侠盗猎车手》等热门的电子游戏快速渲染图形,但在这个过程中,深度学习的研究人员意识到,GPU 同样擅长运行支撑神经网络的数学。基于这些芯片,神经网络能够在更短的时间内从更多的数据中进行学习。
2006 年,英伟达推出 CUDA(Compute Unified Device Architecture,统一计算架构),极大地简化了并行编程的复杂性,使得开发者能够轻松地为装有 GPU 的电脑编程,让电脑不仅能够处理图形设计任务,还能够进行高效的数据运算。实际上,这样的电脑在性能上已经相当于一个超级计算机,成本却大大降低,这使得高性能计算变得更加普及。
2009 年深秋,一位六十多岁的学者从加拿大多伦多来到美国西雅图,由于腰椎间盘有伤,他几乎无法弯腰或坐着,只能躺着或站着,但他还是坚持和当地微软实验室的同仁开启了一个项目——利用之前的研究成果打造一个原型,训练一个神经网络来识别口语词汇。
这位学者就是多伦多大学计算机科学系教授杰弗里 · 辛顿(Geoffrey Hinton),在这个项目中,他们就使用了英伟达的 GPU。在项目组里的人认为 GPU 是用来玩游戏的,而不是用来做人工智能研究的时候,辛顿当时直言,如果没有一套完全不同的硬件,包括一块价值一万美元的 GPU 显卡,这个项目就不会成功。

杰弗里 · 辛顿,图片来源:多伦多大学
2012 年 10 月,辛顿和他的两名学生——亚历克斯 · 克里哲夫斯基 ( Alex Krizhevsky ) 、伊利亚 · 苏茨克维(Ilya Sutskever),在 ImageNet 图像识别比赛上拿了冠军,并且发表论文介绍了AlexNet 架构,而他们训练这种全新的深度卷积神经网络架构仅用了两块英伟达 GPU。
AlexNet 团队参赛的时候发现,如果用 CPU 来训练 AlexNet 需要几个月的时间,于是他们尝试了一下英伟达的 GPU,没想到用两张 GTX 580 显卡只花了一周的时间就完成了 1400 万张图片的训练。这场比赛不仅加速了神经网络研究的发展,更是让 GPU 进入了更多 AI 研究者、工程师的视野——很快,互联网公司和高校实验室就开始向英伟达订购 GPU。
英伟达自然也意识到了 GPU 对于 AI 加速计算的重要性,并开始着重布局专门用于 AI 训练的 GPU 产品。2016 年,黄仁勋向 OpenAI 捐赠了首台 DGX-1,并在上面写到:To Elon & the OpenAI Team! To the future of computing and humanity. I present you the World's First DGX-1!(致埃隆和 OpenAI 团队!致计算和人类的未来。我为你们呈上世界上首台 DGX-1!)

黄仁勋向 OpenAI 捐赠 DGX-1,图片来源:马斯克社交媒体账号
六年后,OpenAI 的 ChatGPT 掀起大模型浪潮,开启了对算力的新一轮紧迫需求;后面的故事大家都知道了——英伟达的 GPU 和数据中心迎超强劲爆发,一年内利润暴涨 8 倍,一卡难求。
而英特尔,逐渐被英伟达甩开了。
根据 Counterpoint 的数据,2022 年 Q4 英特尔的数据中心还有 46.4% 的市场份额,但是由于在 AI 芯片领域的竞争力不足,2023 年 Q3 其市场份额降至 19.1%;而英伟达数据中心的市场份额则一路走高,从 2022 年 Q4 的 36.5% 增长到 2023 年 Q3 的 72.8%。
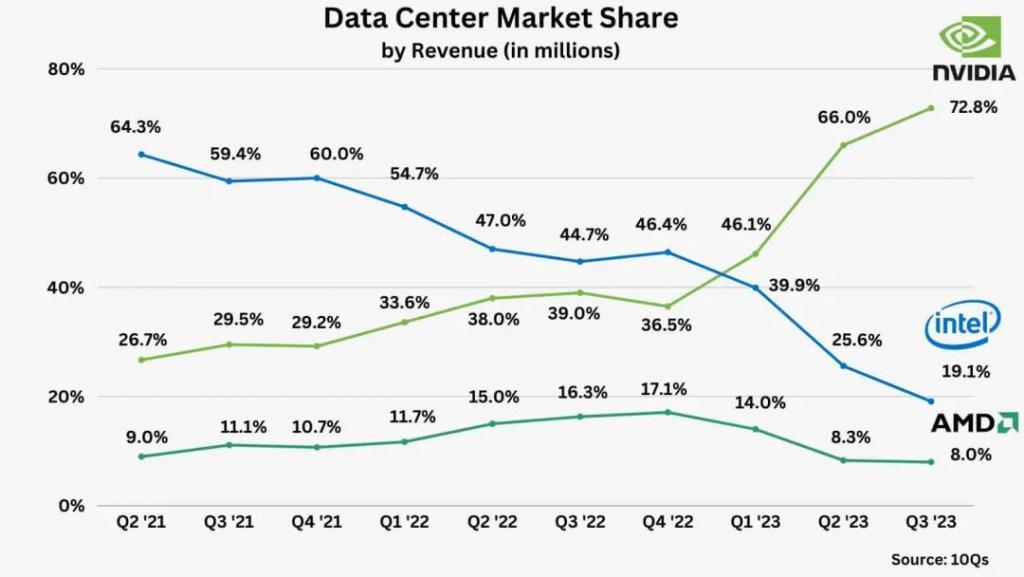
英伟达、AMD、英特尔的数据中心市场份额变化,图片来源:Finbold
如今,英伟达是 AI 领域绕不过去的名字。四年前,当 27 岁的英伟达市值首次超过英特尔时,这被看作 " 一个时代的终结 "。而到了今年 6 月 6 日,当英伟达市值达到 3.01 万亿美元时,其市值已是英特尔的 23 倍。
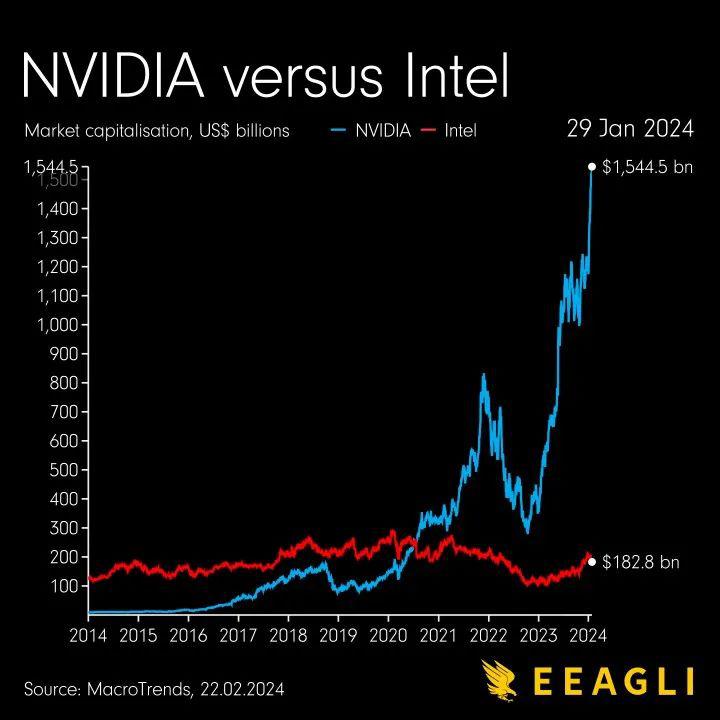
英伟达和英特尔市值对比(图表数据截至 2024 年 1 月),图片来源:EEAGLI
英伟达超越英特尔并不是研发出了比英特尔更强的 CPU,也不是强行新建生态,而是先融入到英特尔的生态中,再利用其独特优势,瞄准 GPU 进行单点突破,让用户逐渐减少对 CPU 的依赖,转而加强对 GPU 的依赖,最终建立自己的生态。
最终的结果是,由于需求的减少,CPU 的迭代速度变慢,而 GPU 的迭代速度在加快。
去年,英伟达发文宣布了 " 黄氏定律(Huang's Law)",该定律预测 GPU 将推动 AI 性能实现逐年翻倍。与摩尔定律关注于晶体管数量的翻倍不同,黄氏定律着重于 GPU 在 AI 处理能力方面的增长。在过去十年中,英伟达 GPU 的人工智能处理能力增长了 1000 倍。
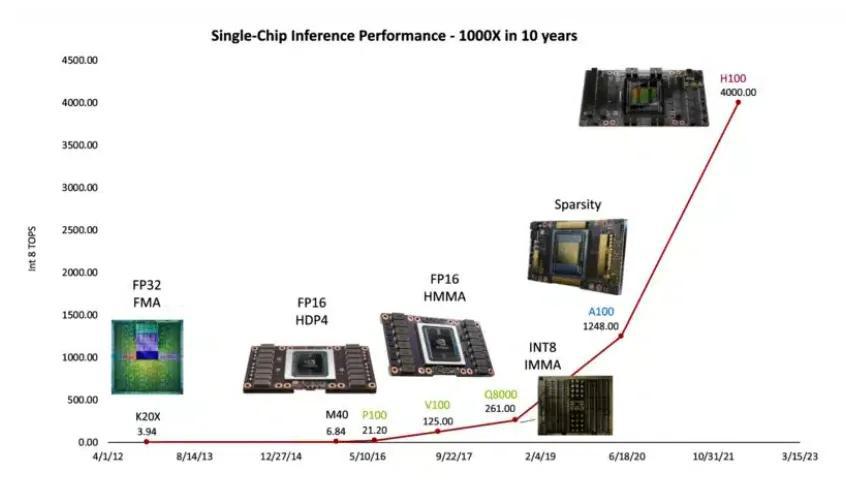
单芯片推理性能变化,图片来源:英伟达
黄仁勋在 Computex 2024 的主题演讲中特意晒出了 CPU 和 GPU 的对比图,并表示,CPU 性能的扩展速度无法再跟上数据持续呈指数级增长的速度,但还有一个更好的办法就是加速计算。
"CUDA 增强了(原本由)CPU(提供的计算能力),卸载的同时加速了更适合由专用处理器处理的工作负载。事实上,性能提升十分显著,随着 CPU 扩展速度减慢并最终基本停止,答案显而易见,加速计算才是解决之道。" 黄仁勋说。
黄仁勋在 Computex 2024 的主题演讲,图片来源:英伟达
如果要用一个词总结英伟达的打法,那就是 " 异构 "。
英伟达所做的 " 异构 ",就是把算力的提供方从 CPU,变成 CPU+GPU。这种创新架构带来的性能提升是惊人的,加速 100 倍,而功率仅增加约 3 倍,成本仅上升约 50%。" 我们在 PC 行业早已实践了这种策略。在数据中心,我们也采用了同样的方法。" 黄仁勋说。
英伟达在今年 GTC 推出的 GB200 超级芯片就是由两张 B200 Blackwell GPU 和一张 Grace CPU 组成。这种组合提供了强大的推理能力,特别是在处理大语言模型时,推理性能比 H100 提升了 30 倍,成本和能耗降至原来的 1/25。

GB200 超级芯片,图片来源:英伟达
英伟达超越英特尔,不是一个新的 CPU 的故事,也不是 GPU 取代了 CPU 的故事,而是 CPU+GPU 异构的硬件形态逐渐地取代了 CPU 集群的故事。
英伟达的打法,对如今的 AI 芯片公司有很大的借鉴意义——跟巨头竞争,可以不走 " 替代 " 的逻辑,而是进行 " 配比 " 的艺术,在原有的游戏规则下把单点拉满,拉到原有霸主追不上,进而扩展自己的生态位。
那么,新的单点是什么呢?
2. 寻找新的单点
现在算力行业的痛点是,英伟达的芯片太贵、供不应求,对于国内用户来说,还要加上高性能芯片无法通过合法渠道买到这一条。
尽管其它芯片厂家也在追赶英伟达,推出各种 AI 芯片。但是,某芯片厂商大模型专家陈风(化名)告诉「甲子光年」,想要提升算力,必须在软件和硬件两方面同步发力,而英伟达的 CUDA 和其硬件的适配体系做得太好,以至于在算力利用率上,其他厂商很难望其项背。
" 就以 AMD 为例,单卡算力是 383TFLOPs,已经比英伟达的某些卡要高了,但是算力的利用率就是比英伟达低,为什么呢?因为软件没有办法充分发挥硬件的性能。大家都能做 7 纳米又如何?你即使是用 7 纳米的芯片,算力利用率也做不过英伟达 320TFLOPs 的 GPU。" 陈风说。

AMD 与英伟达算力对比,图片来源:财通证券
不过英伟达的这种算力集群,也是规模不经济的。如今,大模型巨大的边际成本也已经成为其商业化最大的障碍。红杉资本透露,AI 行业去年仅在英伟达芯片上就花费了 500 亿美元,但产出的营收只有 30 亿美元,投入产出比为 17:1。
有芯片厂商意识到,英伟达的好和贵,是把自家单卡产品叠叠罗汉、加上 NVLink、NVSwitch 和 Infiniband 等互联技术和 CUDA 平台,构成一个封闭的体系实现的。如果参考英伟达超越英特尔的方式,不跟英伟达硬拼 "CPU+GPU",而是去找一个新单点,用 "CPU+GPU+ 新单点 " 的体系,慢慢侵蚀掉英伟达封闭昂贵的旧体系,是不是就能把价格打下来,同时解构掉英伟达原来的优势地位了呢?
那么,这个新单点是什么呢?
把目光放到需求端,一切似乎都有了答案。
目前,以 GPT 为代表的大模型主要是Transformer 架构,这一架构的特点就是相当吃显存。
这不只是因为 Transformer 模型通常包含大量的权重参数,更是因为自回归算法让 Transformer 模型在处理序列数据时,每增加一个输入序列的长度,就需要更多的显存来存储该序列的嵌入向量、键(key)、查询(query)和值(value)向量,以及中间计算的隐藏状态,特别是自注意力机制的计算复杂度还与序列长度的平方成正比;同时,Transformer 每层都会产生大量的激活张量,这些张量在反向传播期间用于计算梯度,也需要暂存在显存中 …… 种种因素,导致随着输入序列长度的增长,显存占用迅速上升。
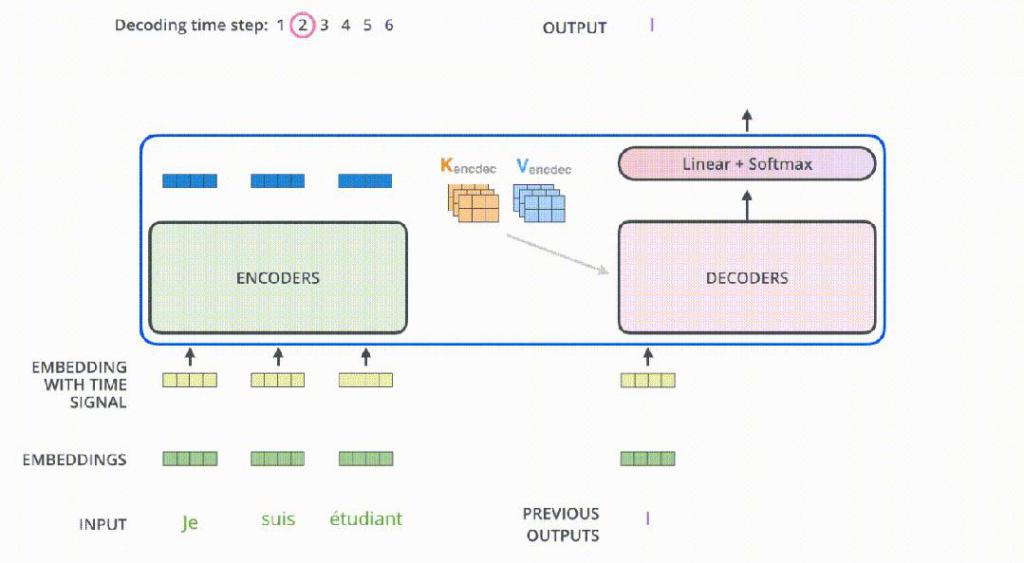
Transformer 架构运行过程,图片来源:Jay Alammar
针对大模型推理这类访存密集型的任务,显存及其带宽会明显限制其对算力的利用,因此在考虑算力需求的时候,似乎也不能单单考虑 FLOPs 的需求,显存容量及带宽同样重要。
在大模型的游戏规则下,显存容量、显存带宽以及互联带宽变成了最核心的竞争力,而算力的重要性和优先级则在默默向后排。
做一张 " 显存指标很高的新型计算卡 " 就是新的单点,这就给其它芯片厂商提供了一个和英伟达竞争的新思路——向着显存,全速前进。
3. 大胆假设,小心求证
季宇就是这么想的,作为英伟达的粉丝,他希望用英伟达的方式超越英伟达,也因此将目光聚焦在了大模型对显存的需求上。
季宇毕业于清华大学计算机系,博士期间一直专注于神经网络加速器、编译器和面向系统优化的机器学习的研究,毕业后作为华为 " 天才少年 " 在海思从事昇腾编译器架构师相关工作。2023 年 8 月,他创立了行云集成电路,主要致力于研发下一代针对大模型场景的 AI 加速计算芯片。
具体来说,行云集成电路希望做一张 " 显存指标很高的新型计算卡 ",通过 "CPU+GPU+ 新型计算卡 " 的组合,去应对大模型推理时访存密集的各种任务,进而把 " 显存 " 这一单点拉满,成为与英伟达体系相抗衡的存在。
" 大模型有巨大的显存需求是业界的共识。在英伟达也在不断提升 GPU 的显存规格来满足市场需求,但我们希望用两张卡,也就是一张算力密集的卡、一张访存密集的卡来解决这个问题。两张卡的方案里面,算力密集的那张卡甚至可以是英伟达的 GPU。" 季宇说。
季宇也特别在意 " 异构 "," 不过我讲的‘异构’是类似过去 CPU 和 GPU 这种不同产品生态位的异构,今天算力行业说得很多的‘异构’是指同一个芯片生态位下不同芯片的异构,比如不同的 AI 芯片 "。行云集成电路的定位是一家芯片厂商,而非算力运营商," 我们是卖卡,英伟达和服务器厂商什么关系,我们就和服务器厂商什么关系 "。
对于生态,季宇认为任何繁荣的产业都需要一个开放的生态体系,也就是一个 " 白盒 ",大模型产业也不例外。但英伟达是一个封闭的体系,把算力、内存、互联等各项标准都做得很强,导致自己的黑盒体系越来越有竞争力、也越来越封闭。
" 今天有太多公司为了跟英伟达的这套体系竞争,既要做单卡、又要做互联、服务器、网络,自建和英伟达对标的私有体系投入巨大,也极其困难,如果能给业界塑造一个可扩展的白盒体系,让体系内的参与者在每个维度与英伟达充分竞争,把英伟达的这套私有体系的力量打散,或许能有与英伟达体系博弈的机会。" 季宇告诉「甲子光年」," 当然英伟达也可以在每个维度做到非常领先,只是它的溢价一定会被越来越强的同行给稀释罢了。"
不过季宇也坦言,目前产品还没出来,一些假设也有待论证。目前最重要的是吸引更多志同道合的人才、合作伙伴,踏实做好研发工作。
长期关注半导体行业的新鼎资本合伙人刘霞认为,这种新的 AI 芯片竞争思路可以更好地满足不同的应用需求,在某些特定的场景下会产生更好的效果和性价比。"这种方案的确很有启发性,但是也有困难和风险,涉及到各个厂商之间的高度的协作和协调,也涉及到技术指标、利润分配等各种复杂的问题,需要在研发过程当中,不断的适配新场景,不断的探索和优化。" 刘霞说。
鲁民投上海投资总监杨浩也表示,这种联合全行业做白盒生态的思路非常新颖," 现在大家都想挑战英伟达,但是确实生态跟不上,国内只有少部分公司在做。如果能通过新型产品打开突破口,建立一个新的生态的话,前景确实值得期待。"
然而,在国内某芯片初创公司工程师刘永(化名)看来,行云集成电路提出的新思路,还有待讨论。
" 目前主流扩显存的方式是在一张卡里把 GPU 和 HBM 的配比做到均衡,然后利用片间互连的方式,将多张这样的卡相连接,共同为大模型提供服务。这种方式能够实现显存的扩展,也可以充分利用其他卡的算力资源,实现并行计算,同时高效的数据交换和同步。" 刘永说。
刘永认为,行云集成电路的确提出了一种新颖的设计方式,可以显著扩展可用显存容量,从而能够处理更大规模的模型和数据集,超越单卡显存容量的限制,在大显存卡上可能会颠覆现有的存储层次结构(多级 cache+HBM 的方案),设计可能会更简单,也有更多面积可以用到 HBM 上,成本更低、容量更大。
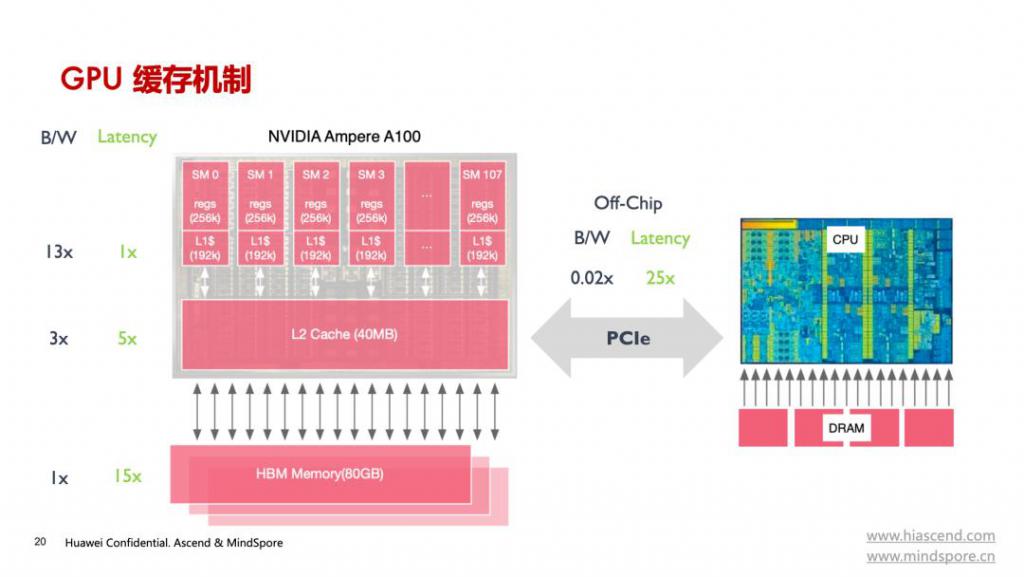
GPU 缓存机制,图片来源:ZOMI 酱
刘永提到的 HBM(High Bandwidth Memory,高带宽内存)是一种先进的存储技术,专为需要大量数据吞吐量的应用场景设计,非常适合用于 AI 加速计算,HBM 也是制约单芯片能力的最大瓶颈之一。
HBM 将多个 DRAM 芯片通过硅中介层(interposer)堆叠在一起,并直接连接到 GPU 或其他处理器,而不是像传统内存那样通过主板上的内存插槽连接。由于每个 DRAM 层都能够通过短路径直接与处理器通信,减少了数据传输的延迟,因此 HBM 的这种三维堆叠结构极大提高了显存容量和能力。
但 HBM 技术涉及到先进封装工艺,也是国内被外部限制的领域,想靠 HBM 扩大显存,阻力重重。
"HBM 的成本几乎占据了一张芯片成本的 50%,而且现在国内能做 HBM 的企业不多,只有长鑫存储,但是长鑫存储的工艺较之台积电、日月光还是落后一点。HBM3E(最新一代 HBM)还在流片过程中且质量不稳定,而英伟达 Blackwell 架构的 GPU B100 已经用上 HBM3E 了。" 昇腾大模型训练专家、B 站 AI 科普视频 UP 主 ZOMI 酱告诉「甲子光年」。
由此看来,大模型和 GPU 是明战,HBM 则是暗战。
甲子光年智库认为,AI 生产时代,算力是生产力的压舱石。这里面最大的命题是,要解决算力供需结构的矛盾。整个 " 算力江湖 " 的构成是极其复杂和多元的,并不存在一个能够统领全局的 " 铁王座 "。
虽说技术对芯片至关重要,但芯片更需要的是市场。
英伟达用一种方式超越了英特尔,谁能说不会出现新的挑战者,用英伟达的方式与英伟达抗衡呢?
" 东风不与周郎便,铜雀春深锁二乔。" 在芯片的 " 战争 " 中,不少芯片厂商如同江东的将士们一样,已经做好了准备," 只待风来 "。
-

- 交卷!GPT-4o 大战国产 AI 模型写 2024 高考作文,今年谁能交出「满分作文」
-
2024-06-11 06:18:12
-
- 上海土拍取消最高溢价率限制?规划部门回应:属实
-
2024-06-09 16:00:26
-
- 海底捞股东会回应热点:加盟模式会谨慎推进,未来将策略性寻求收购优质资源
-
2024-06-09 15:58:10
-
- “热辣滚烫”天气袭击,衍生品工具助力驾驭“对冲术”
-
2024-06-09 15:55:54
-
- 中信建投:铝板块基本面扎实,预期差修正的力量不容小觑
-
2024-06-09 15:53:38
-
- 小米机器人:正推进仿人机器人在自有制造系统分阶段落地;将在北京建设首个通
-
2024-06-09 15:51:22
-
- “监控重点”浮出水面,程序化交易重要规则有望出炉
-
2024-06-09 15:49:06
-
- 招商证券:五月预计新增社融1.5万亿左右,增速8.4%
-
2024-06-09 15:46:50
-

- 比亚迪董事长王传福:“卷”是一种竞争,是市场经济的本质
-
2024-06-09 15:44:34
-
- “木头姐”警告:拒绝马斯克薪酬方案特斯拉可能退市
-
2024-06-09 15:42:18
-
- 补短板防风险,金融严监管释放强信号
-
2024-06-09 15:40:02
-

- 曾经的全职妈妈,正在小红书上“偷偷赚钱”
-
2024-06-09 00:41:45
-

- 一个哪够?是时候让一群AI替你打工了
-
2024-06-09 00:39:30
-
- 出海“四小龙”进击,速卖通能否收回“失地”?
-
2024-06-09 00:37:14
-
- 报告:从数智力到数智化管理与经营的一体化实践
-
2024-06-09 00:34:58
-

- 华为乾崑智驾真的能让AI像人一样开车吗?
-
2024-06-09 00:32:42
-
- 超聚变的「两幅面孔」
-
2024-06-09 00:30:26
-
- 单日暴跌超 400 亿,「宁王」还能涨回去么?
-
2024-06-09 00:28:10
-

- 大公司“塌房”背后,ESG何以成为未来商业必争之地?
-
2024-06-09 00:25:54
-

- 串串房之苦:有多少人在替房东吸甲醛?
-
2024-06-09 00:23:37
 任正非最新发声:谈了美国制裁、苹果手机、什么是科学等
任正非最新发声:谈了美国制裁、苹果手机、什么是科学等 以家人之名歌曲大全
以家人之名歌曲大全