

AI语言模型大行其道,今年的CVPR,彻底变了?
AI语言模型大行其道,今年的CVPR,彻底变了?
国际计算机视觉与模式识别会议(CVPR)2024 即将于 6 月 17 至 21 日在美国西雅图召开,CVPR 是计算机视觉乃至人工智能领域最具学术影响力的顶级会议之一,其论文评选结果受到学术界的广泛关注,对行业创新产生重要影响。
CV 领域的大神何恺明缺席本次 CVPR 引发关注,他提出的 ResNet 成为计算机视觉领域的流行架构,相关论文的引用数量突破 20 万次,曾经多次获得 CVPR 最佳论文奖。硅星人在检索 CVPR2024 接受论文列表之后,发现的确没有何恺明参与的论文入选,这也是 2009 年后何恺明首次缺席 CVPR 接受论文列表。
此前有消息称,今年 CVPR 拒绝了何恺明参与的三篇论文,其中不乏广受关注的高质量论文。何恺明在今年的 CVPR 提交期限里并没有公开的作为一作参与的重要论文,一些和自己的学生或者其他业界同行协作的论文,没有出现在 CVPR 的列表里。
比如《Return of Unconditional Generation:A Self-supervised Representation Generation Method》,提出了一种名为表示条件生成(RCG)的框架,旨在解决不依赖人工标注标签而直接建模数据分布的无条件生成问题;以及《Deconstructing Denoising Diffusion Models for Self-Supervised Learning》,解构扩散模型,提出一个高度简化的新架构 l-DAE,其核心思想是将低维潜在空间与噪声相结合,从而提高了模型自监督表示学习的能力。前者由何恺明在 MIT 的博士生黎天鸿为一作,后者的合著作者中有纽约大学计算机科学助理教授,DiT 的作者谢赛宁。
另一个有意思的现象是,搜索 CVPR 的论文列表可以发现,黎天鸿和谢赛宁参与的其他多个论文有入选今年的 CVPR。
何恺明一向不以论文多产著称,不过这次的缺席也让人感受到今年 CVPR 的变化。
从关注度上和论文类型上来看,今年的 CVPR 确实处在某种转折点。
获得空前关注
今年 CVPR 的规模空前盛大,2024 年 CVPR 共收到 11532 篇论文投稿,比去年增加了 25%。其中,有 2719 篇论文被接受,录取率保持在 23.6%。投稿数量的增加反映了计算机视觉研究兴趣的日益增加。
![]()
作者人数也有所增加。今年,超过 10000 位作者参与了被接受的论文撰写,去年为 8457 人。有趣的是,今年只有三分之一的作者在 2023 年有论文被接受,这表明有大量新研究人员的涌入。
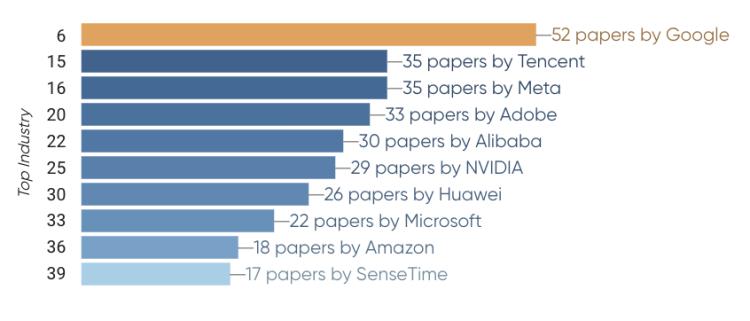
合作仍然是大会的关键。学术界贡献了 39.4% 的论文,但产业与学术界的合作也不容忽视,贡献了 27.6% 的论文。谷歌是最大的产业贡献方,有 52 篇论文,其次是腾讯和 Meta,各有 35 篇论文。
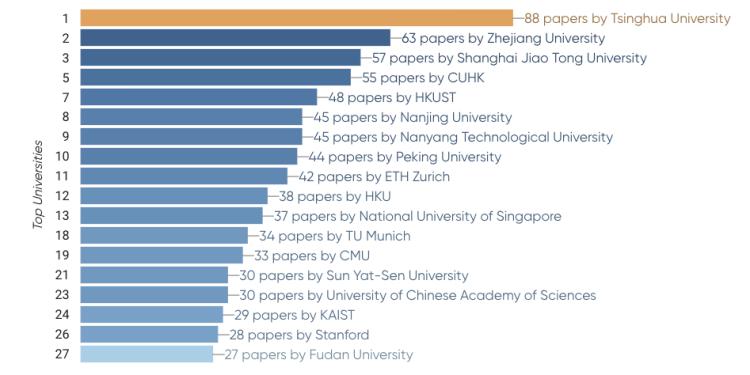
尽管在 CVPR 这类会议上,产业界的影响力很大,但大学依旧是研究活动的主要推动力。顶尖大学每年平均被接受的论文数量超过了 30 篇。根据统计数据,今年表现最佳的大学是清华大学,共有 88 篇研究论文被接受。其次是浙江大学的 63 篇和上海交通大学的 57 篇。
从地理上看,美国和中国是主要的贡献者,占了近 70% 的论文。其他重要的贡献者包括德国、韩国、英国和新加坡。
图像和视频合成与生成最热门,语言视觉结合论文数量增加两倍
具体来看,根据乔治亚理工学院计算机学院对 CVPR 2024 录用数据的统计分析,论文主题涵盖 36 个主题领域。

在大模型时代,CVPR 2024 展示了计算机视觉领域的新趋势。图像和视频合成与生成成为最热门的研究主题,共有 329 篇论文。其次是三维视觉和人体行为识别,分别有 276 篇和 202 篇论文。视觉、语言与语言推理也备受关注,表明学界对多模态信息融合和高层次语义理解的重视。此外,底层视觉、识别任务、机器人与 AI 等领域的研究也取得了显著进展。
而根据数据 AI 模型研发商 LatticeFlow 对论文标题的分析,关于大语言模型的热潮也转移到了 CVPR,结合语言和视觉的研究论文增加了两倍,例如:
OneLLM:One Framework to Align All Modalities with Language
Language Models as Black-Box Optimizers for Vision-Language Models
Inversion-Free Image Editing with Language-Guided Diffusion Models
Towards Better Vision-Inspired Vision-Language Models
A Vision Check-up for Language Models
遵循同样的趋势,用于生成视觉应用的扩散模型也增加了三倍以上。这与行业的发展方向也是一致的,朝向可以理解和生成视觉、语言甚至音频的大型多模态模型。
24 强竞逐 CVPR Award,五分之一来自中国高校
根据官方公布的最新信息,324 篇(11.9%)的论文因其高质量和潜在影响而被审计委员会选为 highlights,90 篇(3.3%)论文被选为 oral talks(优秀论文),oral 当中的 24 篇将竞争本届最佳论文。

CVPR 2024 的最佳论文候选名单覆盖了丰富多样的研究领域,包括视觉与图形、单视图 3D 重建、视觉语言推理、基于医学和物理学的视觉、自主导航和自我中心视觉、3D 技术、行动和动作识别、数据和评估、多视角与传感器融合、低样本 / 无监督 / 半监督学习、地位视觉和遥感、图像与视频合成以及多模态学习。
其中,除了入围的 Transformer、分割模型等,扩散模型方向也有两篇入围,一篇来自苏黎世联邦理工学院的魔改微调,一篇来自英伟达的性能优化。以下是 24 篇入围论文的主题、标题及摘要概览,你认为谁能摘得最终桂冠?
以下为我们整理的入围论文的基本信息,供大家参考:


根据 CVPR 的官方日程,最终的奖项将在当地时间 6 月 19 日早上公布。届时我们也会带来一手的 CVPR 2024 现场直击的内容,敬请期待。
-
- 靠AI造谣、卖裸照赚钱,这些骚操作实在太可恶了
-
2024-06-23 08:56:27
-

- 联想陈振宽:AI 2.0时代,加速布局AI导向的基础设施已成必做题
-
2024-06-23 08:54:12
-
- 联想、华为包揽中国PC市场前二,国产化进程加速落地
-
2024-06-23 08:51:56
-

- 湖南一落马官员贪腐细节披露:非茅台不喝,收受70余箱,被人戏称为“汤茅台”
-
2024-06-23 08:49:40
-
- 油电同权?难啊
-
2024-06-23 08:40:08
-
- 董宇辉,可能是最后一个超级主播
-
2024-06-23 08:37:52
-

- 那个做自己的周杰伦,已经41岁了
-
2024-06-22 23:37:13
-

- 起底变脸90后南通人孙星辰 历时三年 精心策划的旁氏大骗局
-
2024-06-22 23:34:57
-

- 被“仅退款”逼急的商家们
-
2024-06-22 23:32:40
-

- 童颜巨肌!!从瘦弱小伙到IFFB第二,他绝对是中国最该被关注的肌肉男!
-
2024-06-22 23:30:24
-

- 社区支持农业助力乡村振兴
-
2024-06-22 23:28:08
-
- 还等啥?全国最长最刺激玻璃栈道!就在咱保定!票价只要10元!
-
2024-06-22 23:25:52
-
- 咸阳每日资讯 《10月29日看咸阳尽在@咸阳县域 微
-
2024-06-22 23:23:36
-

- 为骂前妻开节目,公开嘲讽前妻便秘,李敖的感情史比他的文学更精彩啊
-
2024-06-22 23:21:19
-

- 关于张丹峰和经纪人的瓜,我有一个清奇的思路
-
2024-06-22 23:19:03
-
- 又一考公巨头,吵架吵上热搜
-
2024-06-22 23:16:48
-
- 朱一龙粉丝又撕金主?汤唯被封杀是骗局?霍建华演技没眼看?
-
2024-06-22 10:10:38
-

- 魔法少女的世界 FGO魔法少女纪行活动公告
-
2024-06-22 10:08:22
-

- 金鸡国际影展丨加场啦!这些佳作不要错过
-
2024-06-22 10:06:06
-
- 50岁的许晴,无人敢娶!
-
2024-06-22 10:03:50
 任正非最新发声:谈了美国制裁、苹果手机、什么是科学等
任正非最新发声:谈了美国制裁、苹果手机、什么是科学等 以家人之名歌曲大全
以家人之名歌曲大全